
2026年05月03日(日)
製薬業界ニュース
京大研究グループ、ビッグデータを使わない薬物候補探索モデルを開発




- TOP
- >
- 京大研究グループ、ビッグデータを使わない薬物候補探索モデルを開発
新着ニュース30件
2017年3月13日 05:30
薬効予測に有効なものを選びとる
京都大学は、3月8日、ビッグデータを使わない薬物候補探索モデルを開発したと発表した。この開発を行ったのは、J.B.Brown医学研究科講師らの研究チーム。同モデルは、化合物の実験データから、薬効予測に有効なものを選びとる新手法となっている。
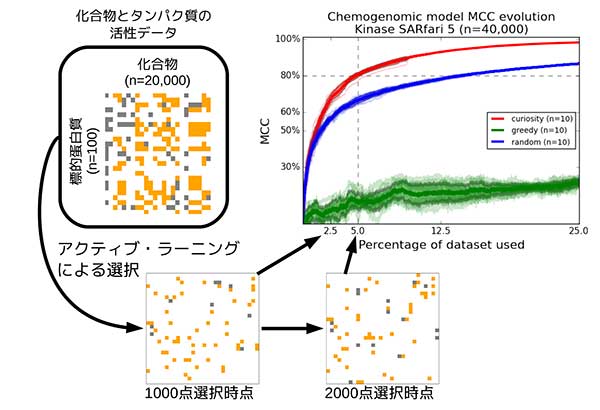
限られたデータから高精度の予測を実現
世界各国では現在、膨大な化合物のデータを用いた新薬の候補物質探索が行われている。探索には膨大な資金と時間が必要だ。そのため、人工知能や数理モデルを用いて望ましい性質を持つ化合物を絞り込む必要があり、バイオインフォマティクスを用いた仮想スクリーニングへの注目が集まっている。ビッグデータ解析は、確かに注目を集めている。しかし薬効の予測に関しては、予測精度をわずかに上げるだけでも膨大なデータを要するという課題もあった。そこで同研究グループは、ビッグデータ解析とは異なる方向で、限られたデータから高精度の予測を実現する手法の開発を推進。シンプルな予測モデルを構築した。
創薬全体のコスト削減に期待
同研究グループは、化合物の構造や過去の実験データより、反応の予測に重要な組み合わせのみを選択。全実験データの10%から20%程度を使用し、予測を行った。結果、データベースに含まれる全ての化合物が治療の標的となるタンパク質と反応するかどうかを、高精度に予測することに成功したという。同研究グループはこの手法について、創薬全体のコスト削減やデータ解析の効率化への利用が期待されるものとしている。
(画像はプレスリリースより)
ビッグデータを使わない薬物候補探索モデルを開発 -化合物の実験データから薬効予測に有効なものを選びとる新手法- - 京都大学
http://www.kyoto-u.ac.jp/

-->